os211
Top 10 List of Week 08
-
User-Level Threads
Kernel-Level threads make concurrency much cheaper than process because, much less state to allocate and initialize. However, for fine-grained concurrency, kernel-level threads still suffer from too much overhead. Thread operations still require system calls. Ideally, we require thread operations to be as fast as a procedure call. Kernel-Level threads have to be general to support the needs of all programmers, languages, runtimes, etc. For such fine grained concurrency we need still “cheaper” threads. -
CFS: Completely fair process scheduling in Linux
CFS is geared for the interactive applications typical in a desktop environment, but it can be configured as SCHED_BATCH to favor the batch workloads common, for example, on a high-volume web server. In any case, CFS breaks dramatically with what might be called “classic preemptive scheduling.” Also, the “completely fair” claim has to be seen with a technical eye; otherwise, the claim might seem like an empty boast.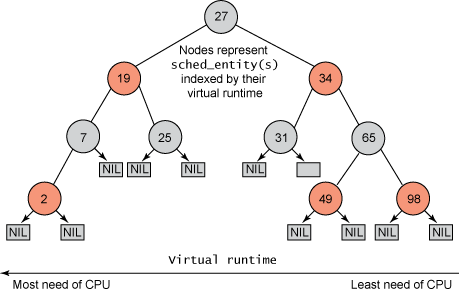
-
Short Term Scheduler
It is also called as CPU scheduler. Its main objective is to increase system performance in accordance with the chosen set of criteria. It is the change of ready state to running state of the process. CPU scheduler selects a process among the processes that are ready to execute and allocates CPU to one of them.
-
What is load balancing?
Load balancing is defined as the methodical and efficient distribution of network or application traffic across multiple servers in a server farm. Each load balancer sits between client devices and backend servers, receiving and then distributing incoming requests to any available server capable of fulfilling them.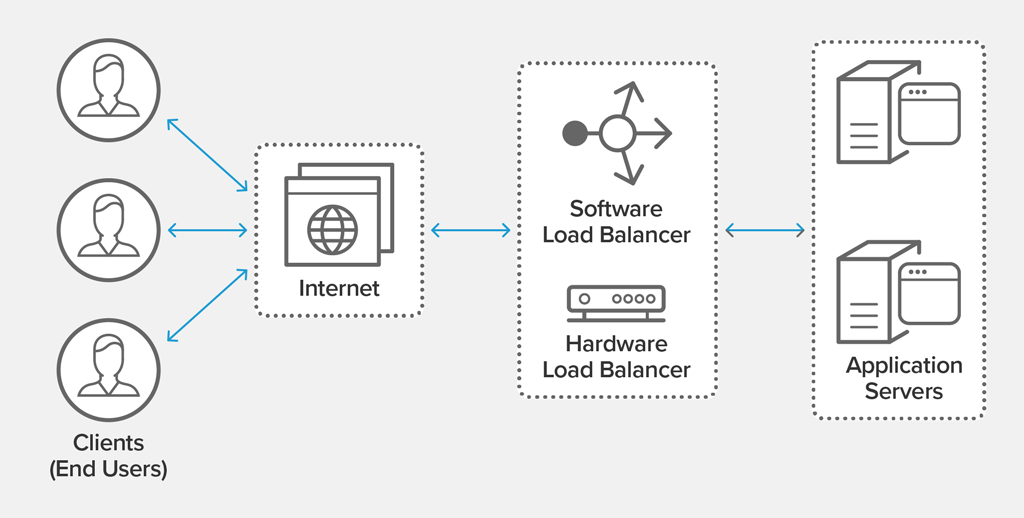
-
Kernel-Level Threads
To make concurrency cheaper, the execution aspect of process is separated out into threads. As such, the OS now manages threads and processes. All thread operations are implemented in the kernel and the OS schedules all threads in the system. OS managed threads are called kernel-level threads or light weight processes. -
NUMA
This era of data centric processing with huge requirement of speed between CPU and memory, gave birth to a new architecture called Non-uniform memory access (NUMA) or more correctly Cache-Coherent Numa (ccNUMA). In this architecture each processor has a local bank of memory, to which it has a much closer (lower latency) access. Mean, we divide the complete available memory to each individual CPU, which will become their own local memory. In case, any CPU wants more memory, it can still access memory from other CPU, but with little higher latency.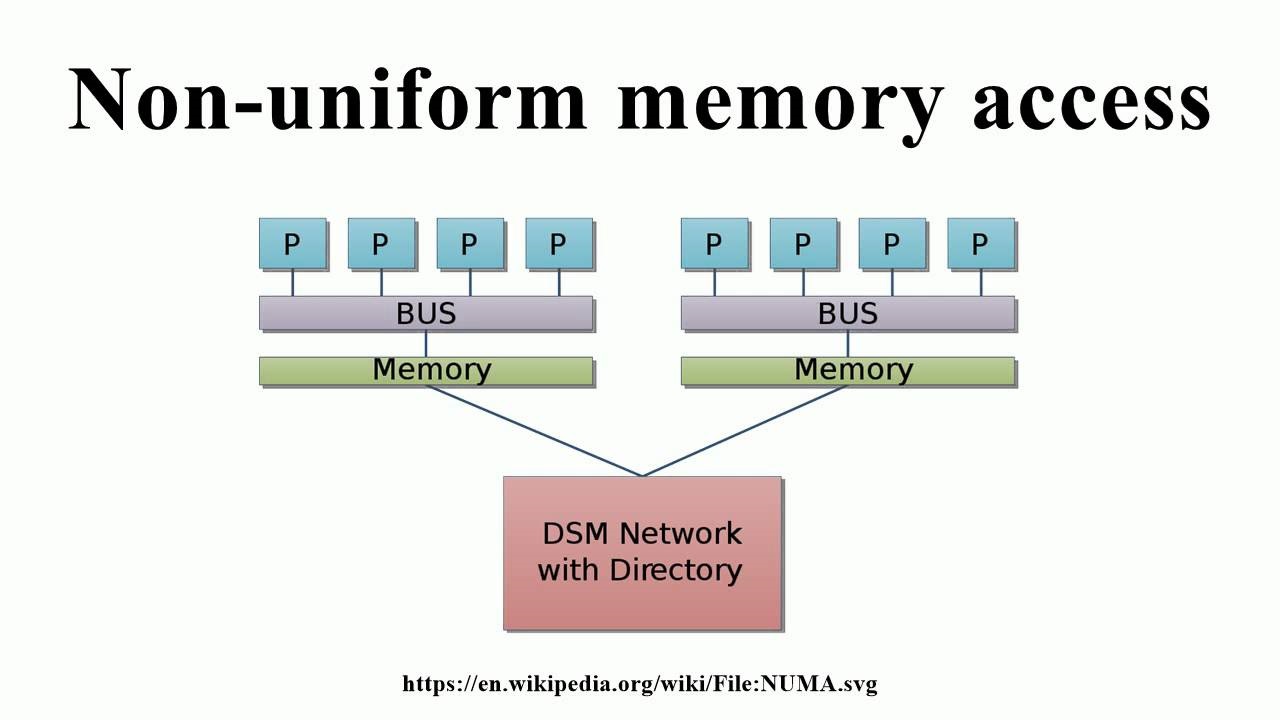
-
CPU Affinity Benefits
The first benefit of CPU affinity is optimizing cache performance. The scheduler tries hard to keep tasks on the same processor, but in some performance-critical situations, i.e. a highly threaded application, it makes sense to enforce the affinity as a hard requirement.A second benefit of CPU affinity is if multiple threads are accessing the same data, it can make sense to bind them all to the same processor. Doing so guarantees that the threads do not contend over data and cause cache misses. -
Asymmetric and Symmetric Multiprocessing
Asymmetric multiprocessing is the use of two or more processors handled by one master processor. All CPUs are interconnected but are not self-scheduling. AMP is used to schedule specific task to CPU based on priority and importance of task. And symmetric multiprocessing is the use of two or more self-scheduling processors sharing a common memory space. Each processor has access to I/O and memory devices. SMP applies multiple CPUs to a task to complete in parallel and faster fashion.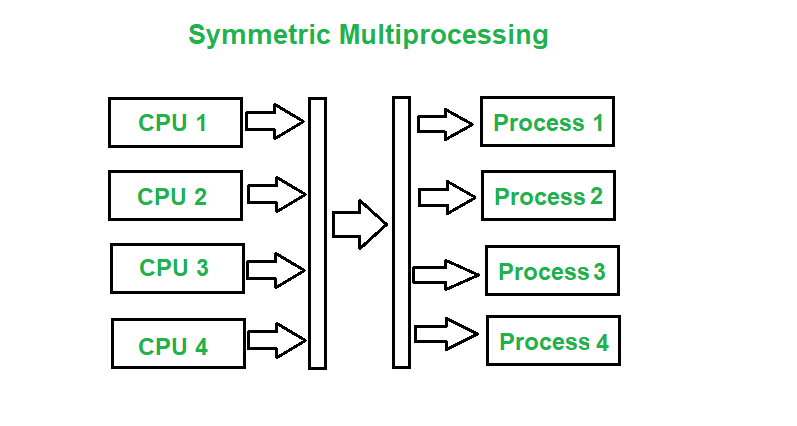
-
What are the different states of a Process?
A process is an active program. It can also be said as a program that is under execution. It is more than the program code as it includes the program counter, process stack, registers, program code etc. Compared to this, the program code is only the text section. A process passes through different states as it executes. These states may be different in different operating systems. However, the common process states are explained below with the help of a diagram below: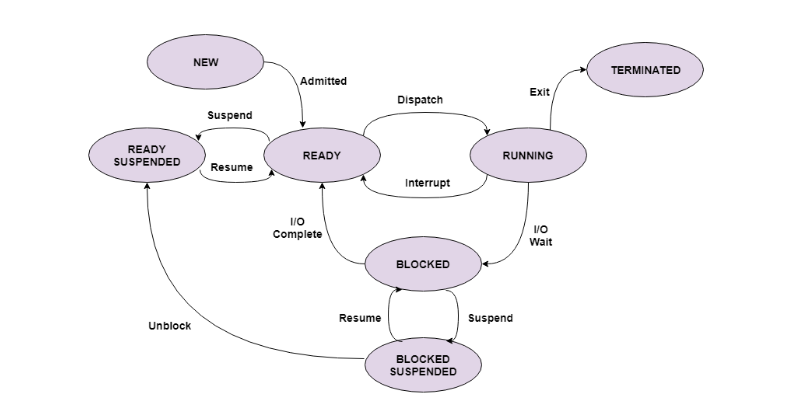
-
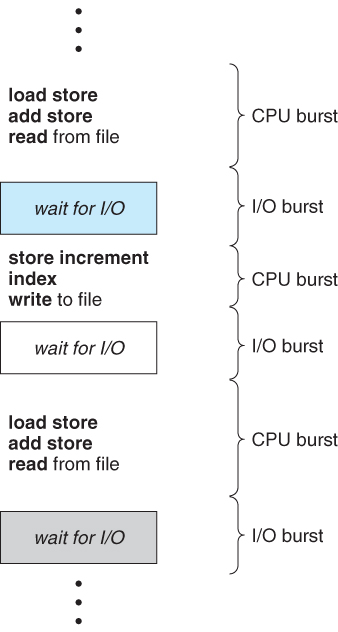
What is meant by CPU Burst and I/O Burst?
Think of a burst as a brief stretch of run as fast as you can go until you cant. A CPU bursts when it is executing instructions; an I/O system bursts when it services requests to fetch information. The idea is that each component operates until it cant. A CPU can run instructions from cache until it needs to fetch more instructions or data from memory. That ends the CPU burst and starts the I/O burst. The I/O burst read or writes data until the requested data is read/written or the space to store it cache runs out. That ends an I/O burst.